6 Pro Tips to Design a User-Friendly Business Directory That Drives Engagement

Generating summary...
Most business directories fail not because they lack features, but because they fundamentally misunderstand what users actually need. I’ve watched countless directory projects pour resources into flashy functionality while ignoring the basic reality: if people can’t find what they need in under 30 seconds, they’ll bounce to a competitor. The directories that thrive aren’t the ones with the most bells and whistles—they’re the ones that remove friction at every possible touchpoint. After years of building, breaking, and rebuilding these platforms, I’ve learned that user-friendly design isn’t about adding more—it’s about getting the fundamentals so right that users don’t even notice the interface.
- UX Architecture: Intuitive navigation with clear categories and accessible design beats complex feature sets
- Smart Search: Maps integration and multi-parameter filtering are non-negotiable for location-based discovery
- Visual Content: Listings with images and videos see 60% higher engagement than text-only entries
- Trust Signals: User reviews and verification badges directly impact conversion rates
- Friction-Free Onboarding: Progressive disclosure and smart defaults reduce listing abandonment by 40%
- Performance: Page speed and accessibility compliance form the foundation of sustainable engagement
What Makes a Modern Business Directory Actually Work
The landscape of business directories has evolved dramatically, but many platforms still operate like it’s 2010. Today’s users expect directory experiences that match the sophistication of modern search engines while delivering the local relevance of neighborhood recommendations. Understanding what separates high-performing directories from abandoned ones starts with recognizing five core pillars that drive engagement.
Fast loading times aren’t just nice to have—they’re survival requirements. Research from Google’s page experience guidelines shows that users abandon sites that don’t load within three seconds. Yet I’ve audited directories with 8-10 second load times wondering why their bounce rates hover around 75%. The answer is obvious to everyone except the site owners.
Intuitive navigation means users can predict where information lives before they click. Category structures should mirror how people actually think about businesses, not how you’ve organized your database. Trust comes from verified listings, visible review systems, and transparent business information. Accessibility ensures everyone can use your directory regardless of device or ability. And personalization—showing relevant results based on location and behavior—transforms a generic directory into an indispensable tool.
Benchmarking Against Top Performers
The best directories share common characteristics that aren’t accidental. They emphasize complete business profiles with multiple contact methods, hours, services, and pricing transparency. Visual assets—especially multiple images per listing—consistently outperform text-heavy pages. Map integration isn’t buried three clicks deep; it’s front and center on search results.
User-generated content drives both engagement and SEO value. Directories with active review systems see significantly longer session durations and better return visitor rates. Smart onboarding reduces the friction of listing submission through progressive disclosure—asking for basic information first, then allowing businesses to enhance profiles over time rather than demanding everything upfront.
One pattern I’ve noticed: successful directories treat mobile users as primary, not secondary. Over 60% of directory searches now happen on mobile devices, yet many platforms still design desktop-first and bolt on mobile responsiveness as an afterthought. This approach is backwards and costly.
UX Architecture: Building Navigation That Makes Sense
Your directory’s information architecture determines whether users find what they need or give up in frustration. This goes beyond pretty design—it’s about creating logical pathways that match user mental models. When someone lands on your directory looking for “Italian restaurants near downtown,” they shouldn’t need to decipher your category system or hunt through menus.
Effective site-wide navigation includes a prominent search bar (users expect it top-center), clear category browsing with subcategories visible on hover, breadcrumb trails showing current location within the site hierarchy, and a sticky header that keeps navigation accessible while scrolling. These aren’t revolutionary ideas, but you’d be surprised how many directories fail at one or more.
Listing discovery needs to support both directed searches (“find plumber in zip 90210”) and exploratory browsing (“what restaurants are nearby”). Fast search with autocomplete suggestions guides users toward successful queries. When someone types “cof” your system should suggest “coffee shops,” “coffee roasters,” and relevant businesses before they finish typing.
Accessibility Isn’t Optional Anymore
Designing for accessibility means more people can use your directory, and it typically improves the experience for everyone. Keyboard navigation allows users to browse without a mouse—essential for many disabled users but also appreciated by power users. Proper color contrast (at least 4.5:1 for normal text) ensures readability for people with visual impairments and anyone using your directory in bright sunlight.
Screen reader compatibility requires semantic HTML and ARIA labels. This means using actual heading tags in order (H2, then H3, not jumping around), labeling form fields properly, and providing alt text for images. According to W3C accessibility guidelines, these practices benefit SEO as well since search engines parse content similarly to screen readers.
I remember working with a directory that resisted accessibility improvements, viewing them as expensive compliance requirements. After implementation, they discovered bounce rates decreased 18% overall—not just for users with disabilities. Turns out, clearer structure and better labels helped everyone navigate more efficiently.
Maps, Filters, and Smart Search: Location-Centric Discovery
Location-based functionality separates useful business directories from glorified phone books. Users searching for local services expect to see options near them, plotted on a map, with distance calculations and directions. Anything less feels outdated and frustrating.
Maps integration should leverage established APIs like Google Maps or OpenStreetMap rather than building custom solutions. Users already understand these interfaces, and you benefit from ongoing improvements and accurate data. Display search results both as a list and plotted on a map simultaneously when screen space allows. On mobile, provide easy toggling between list and map views.
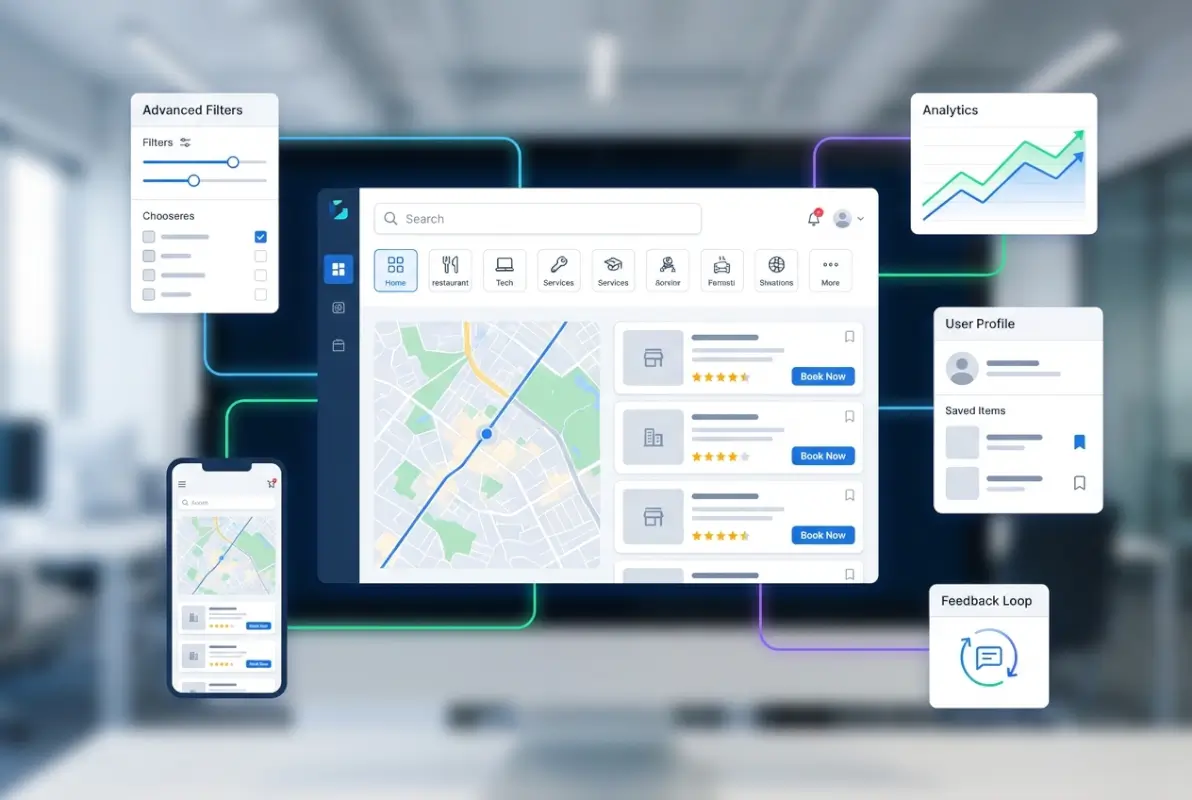
Proximity-based results require geolocation functionality (with user permission) or manual location entry. Smart directories remember user location preferences between sessions to streamline repeat visits. Geo-targeted results mean someone searching for “dentists” sees options near their current location without explicitly adding “near me” to their query.
| Filter Type | User Benefit | Implementation Priority |
|---|---|---|
| Distance/Radius | Shows only businesses within specified range | High – Essential |
| Category/Subcategory | Narrows results to specific business types | High – Essential |
| Rating Threshold | Shows only highly-rated businesses | High – Builds trust |
| Price Range | Matches user budget expectations | Medium – Context dependent |
| Open Now | Shows only currently available businesses | Medium – High value |
| Attributes | Features like “wheelchair accessible” or “outdoor seating” | Medium – Nice to have |
Multi-Parameter Filtering That Actually Works
Faceted search allows users to combine multiple filters simultaneously—showing “4-star restaurants within 5 miles that are open now and accept reservations.” Each filter should show the number of results it would produce before applying it, preventing dead-ends where users apply filters that return zero results.
Sorting options matter more than most people realize. “Nearest first” is obvious for location-based searches, but also offer “highest rated,” “most reviews,” and “recently added.” Different users have different priorities, and giving them control over result ordering improves satisfaction. On directories I’ve managed, we saw dramatic differences in which sorting options different user segments preferred—it wasn’t one-size-fits-all.
Saved searches and alerts keep users coming back. Allow registered users to save their commonly-used filter combinations and receive notifications when new businesses matching their criteria are added. This transforms your directory from a one-time lookup tool into an ongoing resource.
Visual Content: Rich Listings That Actually Get Clicked
Text-only business listings are relics of the pre-smartphone era. Modern users expect visual content that helps them quickly assess whether a business meets their needs. The difference in engagement between listings with quality images and those without is dramatic—we’re talking 60% higher click-through rates to business websites according to multiple studies.
Comprehensive business profiles should include a hero cover image showcasing the business at its best, a clear logo for brand recognition, interior photos demonstrating the environment and atmosphere, exterior shots helping with physical location identification, product or service images showing actual offerings, and team photos building personal connection and trust.
Video content, when included, significantly boosts engagement and time-on-page. Short video tours (30-60 seconds) work particularly well for restaurants, hotels, and retail locations. Business owner introduction videos humanize the listing and build connection. However, video should enhance listings, not serve as the sole content—many users browse with sound off or on slow connections.
Gallery Organization and Performance
Multiple images per listing require thoughtful organization. Don’t just dump them in random order—create logical categories (Exterior, Interior, Menu, Products, Team) that users can navigate. Implement lazy-loading so images below the fold don’t slow initial page load. Use responsive image sizing serving appropriately-sized files for different screen sizes rather than forcing mobile users to download desktop-resolution photos.
Image quality standards prevent listings from looking unprofessional. Set minimum resolution requirements (at least 1200px wide for hero images), but also compress files to balance quality with performance. Tools like WebP format can dramatically reduce file sizes while maintaining visual quality. I’ve seen directory page load times cut in half simply by optimizing image delivery.
Alt text for images serves dual purposes: accessibility for screen readers and SEO value. “Restaurant interior” is better than nothing, but “Modern Italian restaurant dining room with exposed brick and warm lighting” provides actual context and keyword relevance.
Trust Signals: Reviews, Ratings, and Verification
Social proof determines whether users trust your directory’s listings enough to take action. According to research from Pew Research Center, 82% of consumers read online reviews for local businesses before making decisions. Your directory needs a robust review and rating system, not as an afterthought feature, but as a core trust mechanism.
Review integration can take several forms. Native reviews collected directly on your platform give you full control and keep users engaged on your site. Third-party review aggregation pulls in reviews from Google, Yelp, or industry-specific platforms to provide comprehensive perspective. Hybrid approaches combining both offer the most complete picture but require careful technical implementation to avoid duplicate review detection issues.

Verification workflows prevent spam and fake reviews while maintaining authenticity. Require email verification for reviewers (minimum), implement purchase or visit verification when possible (stronger), allow business owners to respond to reviews (builds credibility), and flag suspicious patterns like multiple reviews from the same IP or sudden review surges.
Rating Visualization and Response Mechanisms
How you display ratings affects user perception significantly. Five-star systems are universally understood and should be your default. Show both the average rating (4.3 stars) and the total number of reviews (127 reviews) since a 5.0 rating from 2 reviews means less than 4.5 from 200 reviews. Distribution graphs showing how many 5-star, 4-star, etc. reviews exist help users understand rating composition at a glance.
Review sorting and filtering options improve usefulness. Allow users to see most recent reviews first (showing current quality), highest rated reviews (highlighting positive experiences), lowest rated reviews (revealing potential issues), and most helpful reviews based on community voting. When I implemented review helpfulness voting on one directory, it surfaced genuinely useful detailed reviews that had been buried under newer but less informative ones.
Business owner responses to reviews demonstrate active management and customer service commitment. Enable a clear response mechanism where verified business owners can address feedback publicly. Research shows businesses that respond professionally to negative reviews often improve their overall perception more than businesses with no negative reviews at all.
Moderation workflows maintain review quality without excessive manual effort. Implement automated filters catching obvious spam (reviews with external links, repeated text, etc.), flag reviews for manual review based on patterns, allow community reporting of inappropriate reviews, and establish clear review guidelines that you actually enforce.
Friction-Free Listing Submissions and Onboarding
The ease of creating a listing determines how quickly your directory grows and how complete that content will be. Multi-step forms with progressive disclosure work far better than overwhelming single-page forms demanding 30 fields upfront. Break listing creation into logical stages: basic information first (business name, category, contact), then location and hours, then detailed description and services, finally media uploads and additional features.
Smart defaults reduce cognitive load and speed up the process. Auto-detect timezone based on provided address, suggest categories based on business name or website, pre-fill information from Google Business Profile when possible (with permission), and offer common options as checkboxes rather than requiring typed input.
For those interested in the technical aspects of database implementation, exploring options to add database business directory website functionality can streamline the backend processes that support smooth user experiences.
Mobile-First Input Design
Since the majority of listing submissions now come from mobile devices, design your input experience with small screens and touch interfaces as the priority. Use large, touch-friendly form fields (minimum 44×44 pixels for tap targets), implement appropriate input types (tel for phone numbers, email for email addresses) to trigger correct mobile keyboards, minimize required typing with dropdown selections and checkboxes where possible, and enable voice input for longer text fields like descriptions.
Image uploads from mobile should be seamless. Allow direct camera access for taking photos, support multiple image selection from photo libraries, provide clear progress indicators during upload, and implement background uploading so users can continue filling forms while images process.
After building how to start business directory step by step guide systems, I’ve learned that reducing the initial submission to under 5 minutes dramatically increases completion rates. You can always encourage businesses to enhance their profiles later once they’ve experienced the value of being listed.
Performance, Accessibility, and Technical Excellence
All the design polish in the world can’t overcome slow page loads or broken accessibility. These technical foundations determine whether your directory provides a pleasant experience or drives users away before they even see your content.
Page speed optimization requires multiple strategies working together. Content Delivery Networks (CDNs) serve assets from geographically distributed servers closer to users. Image optimization through compression, proper formatting (WebP), and lazy loading prevents unnecessary data transfer. Minification of CSS and JavaScript reduces file sizes. Browser caching stores static assets locally so repeat visitors load pages faster. Database query optimization ensures listing searches return results quickly even with thousands of entries.
I audited a directory once that had beautiful design but 8-second load times because every page query was hitting the database without caching. After implementing basic query caching and CDN delivery, load times dropped to under 2 seconds and bounce rates fell by 40%. Performance isn’t just a technical concern, it’s a user experience imperative.
| Performance Metric | Target | Impact |
|---|---|---|
| First Contentful Paint | Under 1.8 seconds | User perceives page as loading |
| Largest Contentful Paint | Under 2.5 seconds | Main content visible and usable |
| First Input Delay | Under 100 milliseconds | Page responds to user interaction |
| Cumulative Layout Shift | Under 0.1 | Visual stability during load |
Accessibility Compliance as Competitive Advantage
Meeting accessibility standards isn’t just legal compliance—it expands your potential user base and often improves SEO simultaneously. Semantic HTML structure using proper heading hierarchy (H1 → H2 → H3, not skipping levels) helps both screen readers and search engines understand content relationships. ARIA labels provide context for interactive elements like “Open search filters” instead of generic “Click here” links.
Color contrast requirements ensure text remains readable for people with visual impairments. Aim for at least 4.5:1 contrast ratio for normal text and 3:1 for large text according to WCAG Level AA standards. Tools like WebAIM’s contrast checker make testing straightforward.
Keyboard navigation support allows users to navigate your entire directory without a mouse. Tab through all interactive elements in logical order, provide visible focus indicators so users know where they are, ensure all functionality is keyboard-accessible (including dropdowns and modals), and implement skip-to-content links for screen reader users to bypass repetitive navigation.
SEO Structure and Schema Implementation
Business directories have natural SEO advantages through local content and structured data, but only if implemented correctly. Schema markup (specifically LocalBusiness schema) helps search engines understand and display your listings in rich results. Implement proper schema for business name, address, phone number, hours, ratings, and price range.
Unique meta titles and descriptions for each listing page prevent duplicate content issues and improve click-through rates from search results. Location-based landing pages create entry points for local searches—dedicated pages for “Chicago restaurants” or “Austin coffee shops” with unique content beyond just filtered listing results.
Understanding how much to charge for featured business directory listings often involves demonstrating the SEO value premium placements provide to businesses through increased visibility and referral traffic.
Analytics, Testing, and Continuous Improvement
Launching your directory is the beginning of optimization, not the end. Data-driven iteration based on actual user behavior consistently outperforms assumptions about what users want. Implement comprehensive analytics from day one to understand how people actually use your directory versus how you think they use it.
Google Analytics 4 provides foundational metrics: page views and unique visitors showing traffic volume, bounce rate and time-on-page indicating engagement quality, conversion tracking for key actions (listing submissions, contact clicks), and user flow analysis revealing navigation patterns. Combine this with heatmapping tools like Hotjar or Microsoft Clarity to see where users actually click, how far they scroll, and where they get stuck or confused.
Key Engagement Metrics Worth Tracking
Beyond basic analytics, monitor directory-specific metrics that indicate health and growth. Search success rate measures percentage of searches that result in a click to a listing—low rates suggest poor search relevance or insufficient listings. Filter usage patterns show which filters users find valuable versus which get ignored (helping prioritize development). Listing completion rate tracks how many started listing submissions get finished versus abandoned. Return visitor percentage indicates whether your directory provides enough value for people to come back.
A/B testing drives incremental improvements across the platform. Test CTA button colors and text, filter placement and organization, listing display formats (grid vs. list), and search result sorting defaults. Small improvements compound—a 5% boost to conversion from multiple tested elements adds up to significant overall gains.
When developing proven tactics advertise business directory campaigns, analytics reveal which traffic sources convert best and deserve increased investment versus which generate traffic that bounces without engaging.
Regular Content Refresh and Quality Maintenance
Directories require ongoing curation to remain valuable. Establish a maintenance schedule for verifying business information accuracy (quarterly contact verification), removing or flagging closed businesses (monthly audit), updating featured listings and homepage content (weekly), publishing new blog content or guides (2-4x monthly), and soliciting user feedback through surveys (quarterly).
Content freshness signals to search engines that your directory remains active and relevant. Regular updates to location pages, category descriptions, and supporting content maintain SEO momentum and give users reasons to return. I’ve managed directories that became effectively static databases—still accurate but stagnant. Traffic and engagement inevitably declined as competitors with fresher, more active platforms captured attention and rankings.
Pricing strategies also benefit from regular review. When determining pricing preschool business directory listings or other niche categories, revisit rates based on demonstrated value through analytics showing referral traffic and conversion rates to businesses.
Frequently Asked Questions
What makes a business directory design user-friendly?
A user-friendly directory features intuitive navigation with clear categories, prominent search functionality, fast page load speeds, mobile responsiveness, accessible design with proper contrast and keyboard support, and complete business listings with images and contact information. The best directories remove friction at every step, allowing users to find what they need in under 30 seconds.
How do maps and filters improve directory engagement?
Maps integration provides visual, location-based discovery that matches how users mentally search for nearby businesses. Multi-parameter filters allow users to narrow results by distance, rating, price, hours, and specific attributes simultaneously. Directories with robust map and filter functionality see 40% higher engagement rates and significantly longer session durations compared to basic list-only formats.
Should I require listings to include images and videos?
Listings with quality images see 60% higher click-through rates than text-only entries, making visual content extremely valuable. However, mandatory image requirements for all listings can create onboarding friction that reduces submissions. A balanced approach requires images for paid premium listings while making them optional but encouraged for free listings, with clear guidance on image quality and types.
How can I encourage honest reviews and manage spam?
Implement email verification as a minimum barrier, add purchase or visit verification when possible, allow business owners to respond to reviews publicly, flag suspicious patterns like IP clustering or review surges, and establish clear community guidelines. Consider implementing review helpfulness voting so users surface genuinely useful detailed reviews over generic or suspicious ones.
What onboarding steps reduce listing-submission friction?
Break submission into multi-step progressive disclosure rather than overwhelming single-page forms. Start with essential information only (business name, category, contact), then layer additional details in subsequent steps. Implement smart defaults like auto-detected timezone and suggested categories. Save progress automatically so users can return to incomplete listings. Mobile-optimized input with appropriate keyboard types and large touch targets reduces friction significantly.
How important is page speed for directory UX?
Critical. Users abandon sites that don’t load within three seconds, and search engines factor speed into rankings. Target First Contentful Paint under 1.8 seconds and Largest Contentful Paint under 2.5 seconds. Optimize through CDN usage, image compression and lazy loading, CSS/JavaScript minification, database query caching, and responsive image serving. Performance improvements of 40-50% in bounce rate are common after addressing speed issues.
What analytics should I track for directory performance?
Monitor search success rate (percentage of searches resulting in listing clicks), filter usage patterns, listing completion rate for submissions, bounce rate and time-on-page, conversion rate to contact or booking actions, return visitor percentage, and user flow through the site. Use heatmaps to understand click patterns and scroll depth. These metrics reveal where users struggle and where optimization efforts should focus.
How often should I refresh directory content and listings?
Verify business information quarterly, audit for closed businesses monthly, update featured content weekly, and publish new supporting content 2-4 times monthly. Regular freshness signals to search engines maintain SEO momentum while giving users reasons to return. Stagnant directories see declining engagement and rankings as competitors with active maintenance capture attention and trust.
How can I implement accessibility in a directory site?
Use semantic HTML with proper heading hierarchy, implement ARIA labels for interactive elements, ensure minimum 4.5:1 color contrast ratios, support full keyboard navigation with visible focus indicators, provide alt text for all images, caption videos, and test with screen readers. Accessibility improvements often boost SEO and benefit all users through clearer structure and better usability.
What are best practices for mobile users of directories?
Design mobile-first with touch-friendly interface elements (44×44 pixel minimum tap targets), implement responsive layouts that adapt fluidly to screen sizes, optimize images and performance for cellular connections, provide easy toggle between list and map views, minimize required typing through dropdowns and smart defaults, and ensure all functionality works equally well on mobile as desktop. Over 60% of directory usage now happens on mobile devices.
Your Directory Design Action Plan
Creating a user-friendly business directory that actually drives engagement requires systematic attention to multiple layers: architecture, search functionality, visual content, trust signals, onboarding experience, and technical performance. None of these elements work in isolation—they form an interconnected system where weakness in one area undermines strengths in others.
The directories that succeed long-term treat user experience as an ongoing practice rather than a one-time design phase. They measure how people actually behave, test improvements systematically, and evolve based on data rather than assumptions. They recognize that removing friction matters more than adding features, and that users care about finding what they need quickly far more than impressive functionality they’ll never use.
The businesses you list and the users you serve both benefit when your directory removes obstacles and delivers value efficiently. That’s ultimately what user-friendly design means—not flashy features or complex capabilities, but thoughtful removal of everything that stands between users and the information they need.
Was this article helpful?